2022-05-18/ 商業大數據教育聯盟
由國立中山大學管理學院召集的「商業大數據教育聯盟」於111年5月13日開辦今年度第三場培訓活動,本次主題為《數據分析與機器學習基礎—商業數據分析工作坊》,考量近日疫情,本次活動採線上方式進行,有來自屏東大學管院、高雄師範大學及正修科技大學的教授與同學們同步共同參與學習與交流。
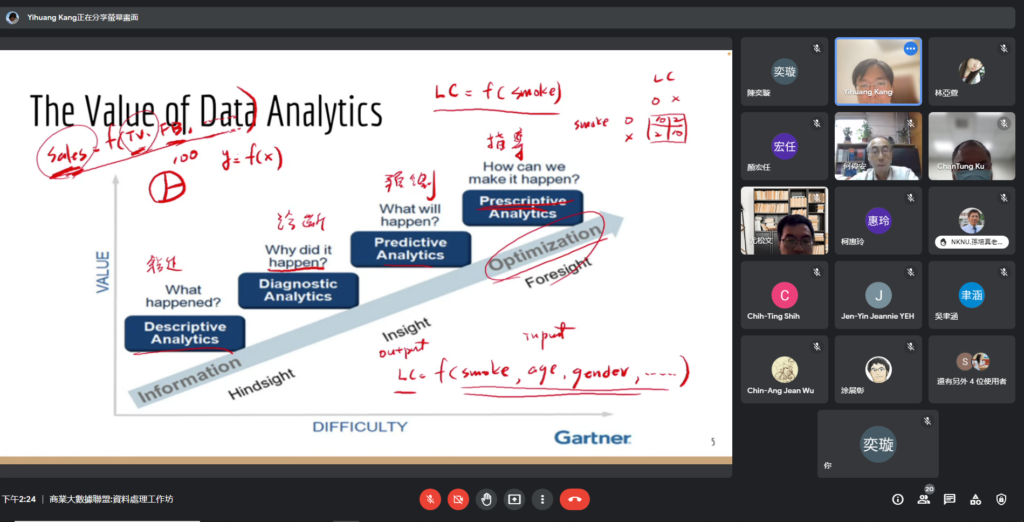
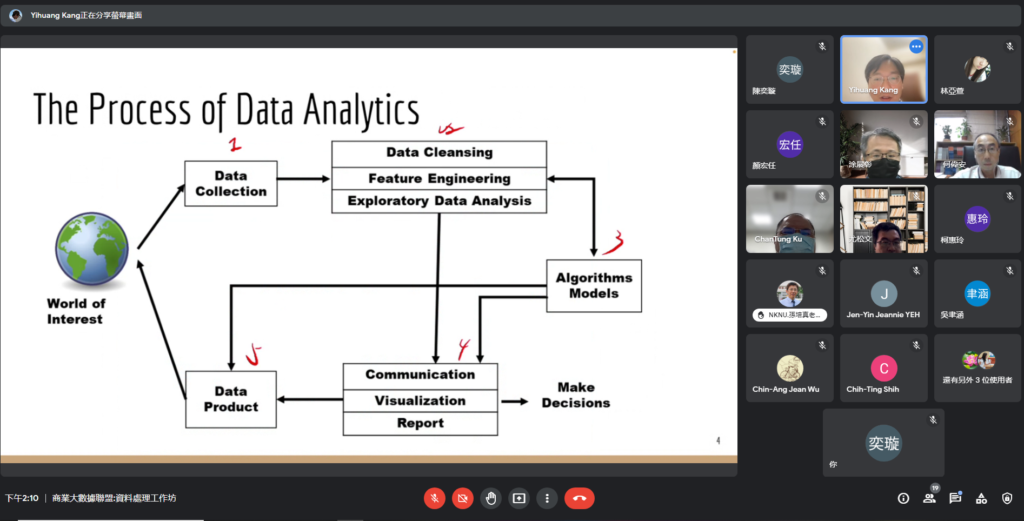
本次的工作坊為商業數據分析第一階段,培訓活動由中山大學資訊管理學系康藝晃教授帶領的團隊介紹數據分析與模型架構設計的基礎,課程中討論了目前相關領域工作者對機器學習的認知,進而逐一講授「數據資料分析的程序」、「如何正確識別模型的準(精)確性」、「模型可解釋性的重要性」及「如何判斷模型是否存有捷徑學習等問題」等主題。課程一開始,康老師以「數據分析的流程」為開端向大家說明數據分析的步驟,它主要可分為資料蒐集、資料清理、建立演算法模型、溝通與視覺化處理及資料處理等階段。康老師集其教學與實務經驗,與學員分享在各個分析階段的重點事項;例如:從顧能(Gartner)公司提出關於數據分析價值的四個層級,大數據分析(Big Data Analytics)定義的演變、以及資料的品質對分析的影響。在瞭解數據分析後,康老師帶著大家了解「機器學習」的基礎觀念和原理,讓學員更清楚認識機器學習的目的、原理、與實務操作,同時也說明統計模型與機器學習兩者間的異同。整體課程內容環繞在數據建模的技巧且進階地探討如何選擇與設計好的模型架構,以協助學員了解如何正確應用模型處理所遇到的分析問題,進一步取得商業分析的最佳解決方案。
接者由古展東助教透過「鐵達尼號」的資料案例加以演示說明,從資料欄位說明、透過R語言的資料套件進行分析與建立預測模型,在助教的帶領下學員們瞭解了模型的訓練步驟。最後,康老師說明建模思考(Model Thinking)、機器學習的建模過程中注意事項、以及最近熱門的多模態的機器學習。康老師也跟學員們強調,模型的建立是非一次性的,需隨觀測現象持續調整模型以求分析效果的最優化。
本次三小時的工作坊透過具體的實作過程,讓參與的老師與同學們都更深入認識數據建模的技巧與真諦,無論是帶領學生做研究或提供企業進行實務市場分析,參與的老師和學員們皆認為對商業大數據人才培育和業界數位轉型發揮更廣泛的效應。此外,在商業大數據教育聯盟的網站(business-analytics.org.tw)上有許多以建立的資源與參考範例,也鼓勵聯盟成員可以多加利用與學習。
(前程文化何偉安副總、中山大學資管碩 古展東同學 撰稿/ 管院編修)